Topics
- Media Art

In this project I play with the implications of sampling and dubbing tape recordings from the John Hutchinson’s sound archive with stochastic processes. Hutchinson, a self-taught field recordist, began capturing these unique sounds in 1959 during his work with the Department of Agriculture. As a result, this archive offers a captivating journey through time and diverse regions of Western Australia. Given the sheer volume of recordings (over 130 hours!), a manual exploration (solely by ear) proved impractical. Instead, I adopted a hybrid data-driven approach to sonic foraging, implementing a sampling mechanism to extract “aural summaries” from the most intriguing parts of the archive. Imagine creating a sonic “thumbnail”, but instead of compressing images we are compressing entire archives by creating representative mosaics with their most salient one-second sound fragments (see a spectrogram representation of the latter in the picture shown above). For this purpose, I used stochastic point processes to select fragments with high diversity. This ensured a representative selection, fast browsing, and avoided the redundancy of (uniform and independent) random sampling. Of course, what counts as representative depends on the task at hand. To address this issue, I relied on Wavelet scattering networks. These are like deep learning networks but with filters defined a priori in terms of Wavelet functions instead of filters approximated from data. Finally, in order to showcase the potentials of this technique, I programmed a bespoke interface to mix the fragments live. The resulting aural exploration was presented at the Data Visualization Institute, University of Technology Sydney.

The interface has a granular sustain. Each fragment has its own track with a send to FX. The balance of effects can be controlled before the master output. The number box next to ‘T’ is for transposition. Loop start and end are shown in samples. Sample # represents a draw from the archive using DPP as described. Since actual files from the archive are retrieved (as opposed to being synthesised), it is possible to use the retrieved fragments as entry points to previously ‘unlistened’ regions (i.e., sonic foraging).
Aural summaries: Unveiling diversity through stochastic sampling
Imagine exploring a vast sound library. How do you quickly grasp its essence without listening to everything?
Let’s put it in a different way, how do you read through the pages of an infinite book of sound without losing your mind? You can’t use bookmarks because the pages fall through your fingers.
I tackled this challenge (and kept my sanity in return) by employing a method called Determinantal Point Processes (DPPs). DPPs are mathematical models originally used to represent the behaviour of fermions (such as electrons), which naturally repel each other (in theory they cannot occupy the same quantum state). This same principle can be applied to sampling sound files! Turns out DPPs can help us to select sub-collections of short audio snippets that are as sonically diverse as possible. Think of it like drawing sounds from a bag but the smart way, you’re guaranteed to pick contrasting textures, avoiding redundancy. Along these lines, a recent paper proposed DPPs to address data exploration in very large audio recordings. This is of great value in ecoacoustics, where audio recordings are made longitudinally for years to understand environmental changes through persistent patterns in soundscape dynamics.
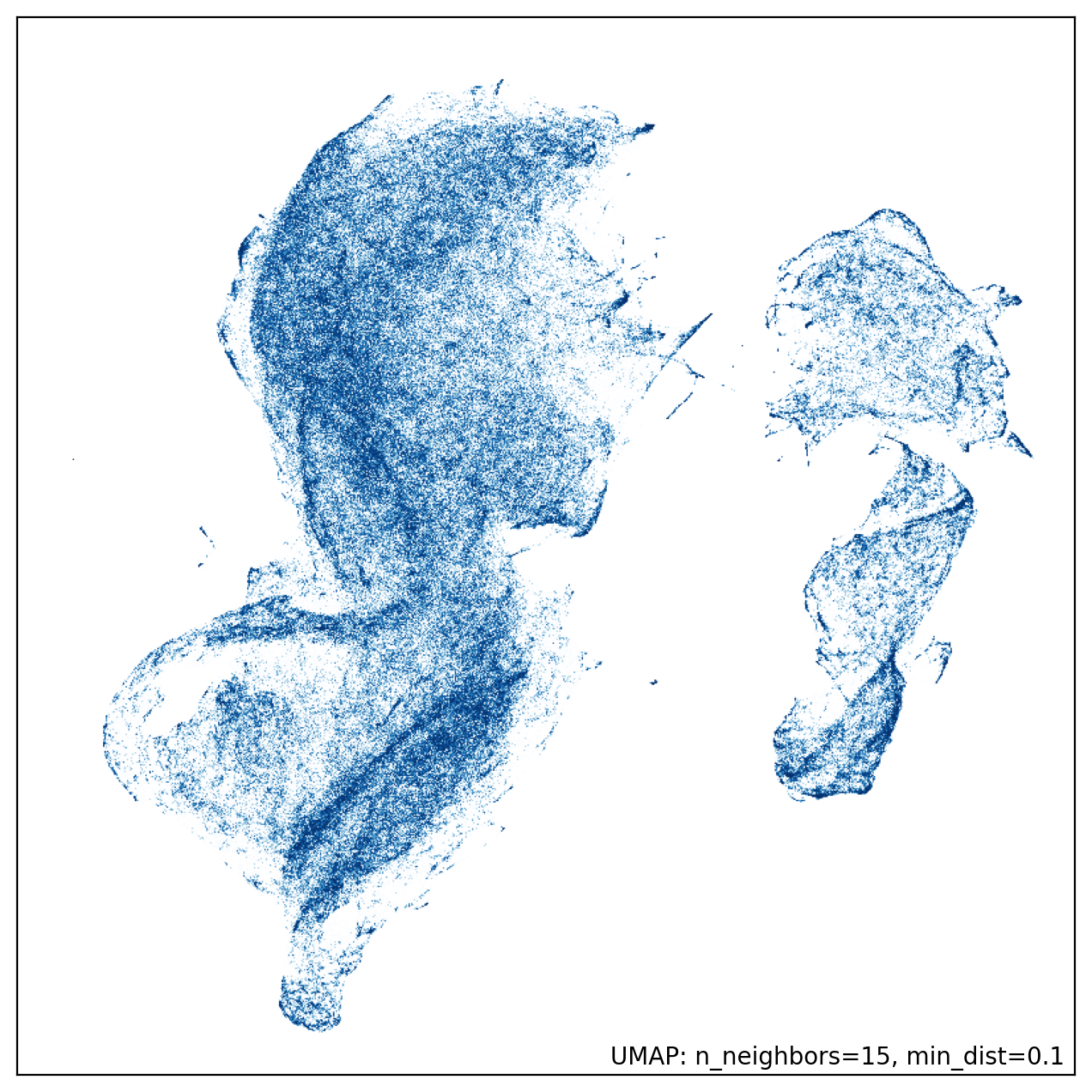
So, how does it work? First, a wavelet scattering network (or for the pros, an adequate feature extractor) is used to analyse each sound fragment, essentially creating a unique “fingerprint” (or feature space) that captures sonic characteristics of interest (see the picture below for a 2D representation of such fingerprints). DPPs then leverage this fingerprint to select audio fragments that differ as much as possible (i.e., repel each other) in the feature space. Unlike other methods which sample fragments uniformly at random, DPPs do not get stuck repeating similar sounds. Intriguingly, this property is given by a mathematical structure from which the processes derive their name: the probabilities of random subsets are assigned according to the determinant of a function. In our case this function is expressed as a matrix of numbers, the output of the Wavelet scattering network for all sound fragments.
Overall, with this approach between high-mathematics and experimental sound sampling, I wanted to push the boundaries of curation and soundscape composition. What a better way to do it than to improvise with a whole archive of wild sounds? These days most generative systems are based on prompts and do not reference their own archival origins. In contrast, with this experimental method of sampling, I advance a new form of creating sound mosaics through archival listening. No longer passively prompting with words, but dubbing and remixing fragments from the archive in real time ala musique concrète. A hot pot of sounds, a mishmash of Wavelets turned Sukiyaki for the ears!
In a more media-archaeological sense, which is a particular mode of inquiry into how media works, I performed the role of a machine learning model. By listening to a batch of 20 windowed 1-second fragments from a whole archive, I attempted to produce soundscapes via improvisation, a genre reflecting the trial-and-error nature of such models. Therefore, the main points put forward by this performance are:
- Most machine learning models do not implement smart-sampling methods like DPP to create training batches (see this for an exception). In this case it was me who curated what DPP had already sampled from the archive.
- Machines ‘listen’ through standardised filtering or data-driven feature extraction and not by tapping into the fully-embodied experience of a human listening and performing before an audience.
- The live-mixing interface displays the potentials of hybridising human and machine capabilities in archive-based soundscape composition. In cultural theory, these cybernetic chimeras appear to have been denoted assemblages or social machines.
Credits and event documentation
Special thanks to Andrew Burrell and Zoë Sadokierski for their support and including my proposal in the programme.

